

流れ 2004年8月号 目次
― 特集:流体情報と融合研究 ―
| リンク一覧にもどる | |
フルードインフォマティクスにおけるデータマイニングと知識発見
 東京大学 人工物工学研究センター デジタル価値工学研究部門 白山 晋 |
1. はじめに
VarianとLymanは,1999年に生み出された情報を1エクサバイトと見積もっている[1].ただし,実際に生み出されたデータはそれ以上のものであったと予測されている.そして,その後の5年間のインターネットのブロードバンド化,個々人に1テラバイト以上の記憶容量を提供し始めたハードディスク装置の大容量化は,膨大な量のデータの広域分散化を加速している.図1において,データの増加を発生源とともに模式的に表した.可視化によって,データは視覚情報に纏められ(無意なものが棄却され),一旦はデータの増加を抑えることに成功したかに思えた.しかしながら,副次的に派生するデータ,陽に表現できないデータ,生み出された視覚情報自身の増加を加えると,消化できないほどのデータ・情報が指数関数的に蓄積し続けている.この状況を打破するために,様々なデータマイニング手法や広域分散型の情報管理システムが提案され,いくつかのものが実際に利用されるようになる.そして,情報の指数関数的な増加から漸増的ものに転じるという指摘もなされはじめている(図1右上).しかし,今後の動向は楽観視できるものではない.たとえ,一握りの専門家が知識を集約していったとしても,知識創成の可能性のあるデータが大多数の個人の側に残されることも事実であろう.課題は,個人の能力差によるデータ・情報・知識の集約度の違いをどのように扱うかである.
流体情報を扱う場合においても,テキストデータ,音声や映像データよりも数値データに比重をおいたデータ分析という違いはあるが,同様にデータの大規模化,分散化が問題になっている.実験におけるデータ取得技術は,点から面,そして空間へと進展し,計算においては時空間の高解像化が進み,パーソナルコンピュータの飛躍的な性能向上によってデータは個人の側に蓄えられることが増えたためである.このような状況の中で流体情報におけるデータマイニング技術の高度利用の必要性が高まっている.
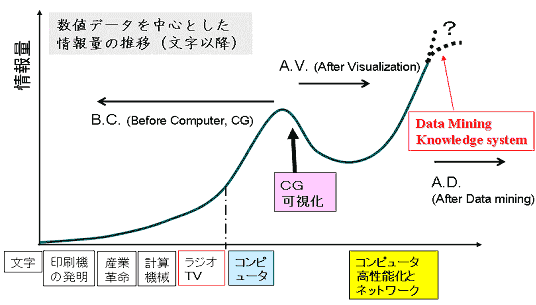
図1.情報の発生源と情報量の推移
2. データマイニング手法と知識発見プロセス
繰り返すようであるが,CFDを例にすると,80年代はスーパーコンピュータの発展も相まって大量に吐き出されたデータではあったが,データの解釈やそれに基づく低次元化(あるいはデータの再構成)は容易であると考えられ,必要な部分だけ取り去れば,一人の研究者でも扱えないほどのデータは残らないだろうという見解があった.ところが,数値解の信頼性の問題を理論的に解決することは難しく,常に更なる高解像度計算が必要とされ,大量のデータが生み出され続けている.結果として有意な部分と無意な部分を分けることすら難しくなっているのが現状である.また,実験においても,PIVなどの広範囲の空間情報を扱う方法が発展し,同様の状況がある.このように多種多様な大規模データが分散して存在し,その処理の問題がクローズアップされているのである.
流体情報を大別すれば,次の4つのものになる.
-
■ プリプロセスに関連する情報(問題設定に絡む情報:形状,物理・設計パラメータ等)
-
■ 生成プロセスに関連する情報(数値計算,実験装置,観測装置)
-
■ ポストプロセスに関連する情報(可視化情報等)
-
■ 応用,展開,フィードバックに関連する情報(流体現象に関する情報,設計情報,制御情報等)
それぞれは独立しているわけではない,さらには細分化した方が良い場合もある.敢えてこのように分類したのは,データマイニングにおいて情報の構造化と階層化が重要な役割を成しているためである.データマイニングは,構造化と階層化の過程,及びそれらの過程の後に生じるデータ,情報に対して効力を発揮する.
さて,注目されることが多くなったデータマイニングではあるが,データマイニング手法の多くは,統計解析(あるいはデータ分析)において用いられる手法と同じであり,確率統計学をベースに発展している.流体解析においては,いうまでもなく乱流の分野,データ処理を中心にして統計解析の利用・応用は盛んであった.それによって得られた知見も多い.では,従来の統計解析との大きな違いはなんだろうか? 多くの教科書ではデータの大規模化とアクセスの容易さを挙げ,母集団に対する直接的なデータの分析(標本抽出を行わないという意味)や交差妥当化(cross validation)に対して十分なデータが存在することを強調している[2][3][4].また,統計的検定論に属する手法などの存在理由がなくなり,そのような淘汰に違いがあるという主張もある.さらに,"学習"というキーワードから,"ニューラルネットワーク"を違いの一つとして採り上げることも多い.敢えてそのように違いを際だたせる必要はないように思われるが,強いて言えば,データマイニングが知識発見プロセスまでをスコープに含めていることが差違であろう.つまり,知識創出過程や知識発見過程への展開が鍵なのである.このため,データマイニングという文脈において,いくつもの知識発見プロセスが提案されている.一例を示そう.Fayyadら[5]は,
-
(ⅰ)DataからTarget Dataへ変換する
-
(ⅱ)Preprocessed DataからTransformed Dataへ変換する
-
(ⅲ)Transformed Dataをクラスタ化するなどしてパターン(Patterns)を抽出する
-
(ⅳ)Patternsから知識(Knowledge)を創出する
というような知識発見のプロセスを提案した.データマイニングと統計解析との違いの一つが知識発見プロセスまでを視野に入れることなので,流体情報を考える上でもこの点に留意すると新たな展開が期待できる.著者らはFayyadらのプロセスを渦構造の抽出過程に適用し,渦構造の変化と物体に働く流体力の分析に利用した(図2,図3)[6][7].その結果,知識発見プロセスの多くは人間の思考パターンを形式化したものであり,作業手順の確定に対しては有用であることを見出すことができた.
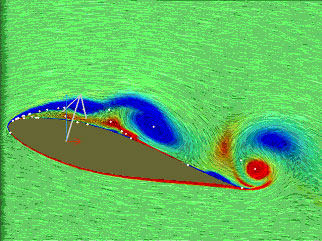 |
| (a)(クリックすると再生 mpg:1MB) |
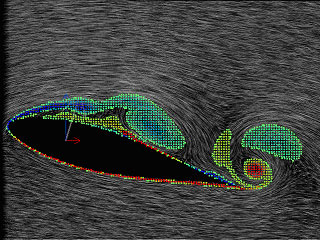 |
| (b)(クリックすると再生 mpg: 3.8MB) |
| 図2. 渦度分布から渦要素へ.左図(a)はピクセル露光法[8]によって可視化した速度場に渦度分布(青色が時計回りの速度場を誘起する渦度,赤色は反時計回りのものを示す)を重ねたものである.右図(b)の点状のものは渦度分布にもとづいて抽出した渦点要素を示している. |
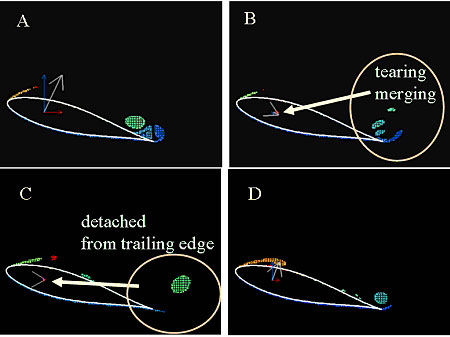
図3. 抽出渦要素による静的失速の説明
3. おわりに
データの大規模化は,流体運動の非線形性を際だたせ,従来的な分析手法の限界を示している.そして,主として非線形性に起因する大きなパラメータ空間の探索と,得られた結果の解釈から知識発見へ至る過程においてデータマイニングを必要としている.そこで,日本機械学会から刊行予定のフルードインフォマティック[9]では,渦構造を特徴領域とした場合の知識発見プロセス,知的可視化戦略,知識ベースの利用,パラメータ推薦システムといういくつかの事例研究を紹介し,それらの中で,データマイニング手法の適用法とそれがどのように知識発見に利用できるのかについて説明することにした.しかしながら,現在のデータマイニング手法に対して万能であるとか,知識を自動的に発見してくれるという考えは捨てる必要がある.「よくよく考えるとそうだ」,「見逃していたことが示される」,あるいは「補助的な情報を半自動的に生成してくれる」のような主として支援情報を提示するものと考えた方がよい.特にドメイン(領域,あるいは分野)の情報や知識の役割が大きい.このため,一般的なデータマイニングをそのまま利用するというよりは,いかにドメインの知識を使うかが鍵となるのである.情報処理技術が進んだとしても流体工学固有の研究の必要性はますます大きくなるだろう.そこにも流体のおもしろさがある.
参照文献
[1] Lyman,P. and Varian H.R.:How much information:See http://www.sims.berkeley.edu/research/projects/how-much-info/
[2] Pieter Adriaans, Dolf Zntinge著,山本英子,梅村恭司訳:データマイニング,共立出版,1998
[3] 豊田秀樹:金鉱を掘り当てる統計学,ブルーバックスB-1325,講談社,2001
[4] マイケルJ.A.ベリー,ゴードン・リノフ:データマイニング手法,海文堂,1999
[5] Fayyad,U., Piatetsky-Shapiro,G. and Smyth, P., AI magazine vol.17, 1996, pp.37-54.
[6] 白山 晋,大和裕幸,航空宇宙技術研究所特別資料SP-46,2000,pp.249-254.
[7] 白山 晋,大和裕幸,日本造船学会論文集第188巻,Nov. 2000,pp.23-31.
[8] Shirayama S. and Ohta,T., Journal of Visualization Vol.4, No.2 (2001), pp.185-196.
[9] 早瀬ら:フルードインフォマティック,日本機械学会編,技報堂出版(株), 2004発刊予定